概览
出于LLM基建需求, 最近以hugging face的Llama实现作为baseline, 通过调用基础算子对Llama进行了C++组网。在组网前, 阅读了一下Llama的论文和hugging face的组网逻辑(modelling_llama.py), 总结了Llama网络的几个主要特点:
- 和GLM类似, 也是使用了RoPE, 且实现和原始RoPE是一致的;
- 没有采用通常的Layer Normalization, 而是使用RMSNorm;
- GLU单元实现不一样, 像GPT、GLM、BLOOM模型的GLU都是两个参数矩阵做FC, Llama的GLU单元有3个参数矩阵, 采用
Swish激活函数; - 采用BPE(byte-pair encoding) Tokenizer方案
- Llama的模型参数重没有
bias;
后面会具体介绍一下RMSNorm、GLU和BPE Tokenizer这三个feature。
RMSNorm
paper: 《Root Mean Square Layer Normalization》
一般的layer normalization的计算可以表示成[seq_len, batch_size, hidden_dim](hidden_dim = size_per_head * head_num), 其中均值
RMSNorm的计算略有不同, 可以表示成hidden_dim这个维度计算得到的。
由于在搭建GLM网络时,layer normalization使用float16数据类型进行计算, 所以一开始RMSNorm也是用float16。后来发现虽然第一层的精度可以对齐, 但是经过多层block后, 精度偏差越来越大。仔细检查了一下, 发现由于float计算后精度可以完全对齐。
SwiGLU
- SiLU激活函数:
- Swish激活函数:
SiLU可以看成Swish的一个特例。
可以看看hugging face上对Llama的SwiGLU的实现, self.act_fn就是Swish激活函数
1 | class LlamaMLP(nn.Module): |
拓展阅读:
BPE
BPE最初是作为一种文本压缩算法,后来被很多的Transformer模型用作tokenization, 比如GPT系列、RoBERTa, BART, DeBERTa。
tokenization(标记化)是将自然语言转换成模型可以处理的标记的过程。自然语言处理的基本对象可以分成3类:1)单词(word); 2)字符(character); 3)子词(subword)。这是一种介于单词和字符之间的处理粒度。BPE就是一种基于subword的处理方法, 还有其它一些subword tokenization方法, 比如WordPiece, Unigram, SentencePiece等。
BPE的一个典型例子可以查看wiki:
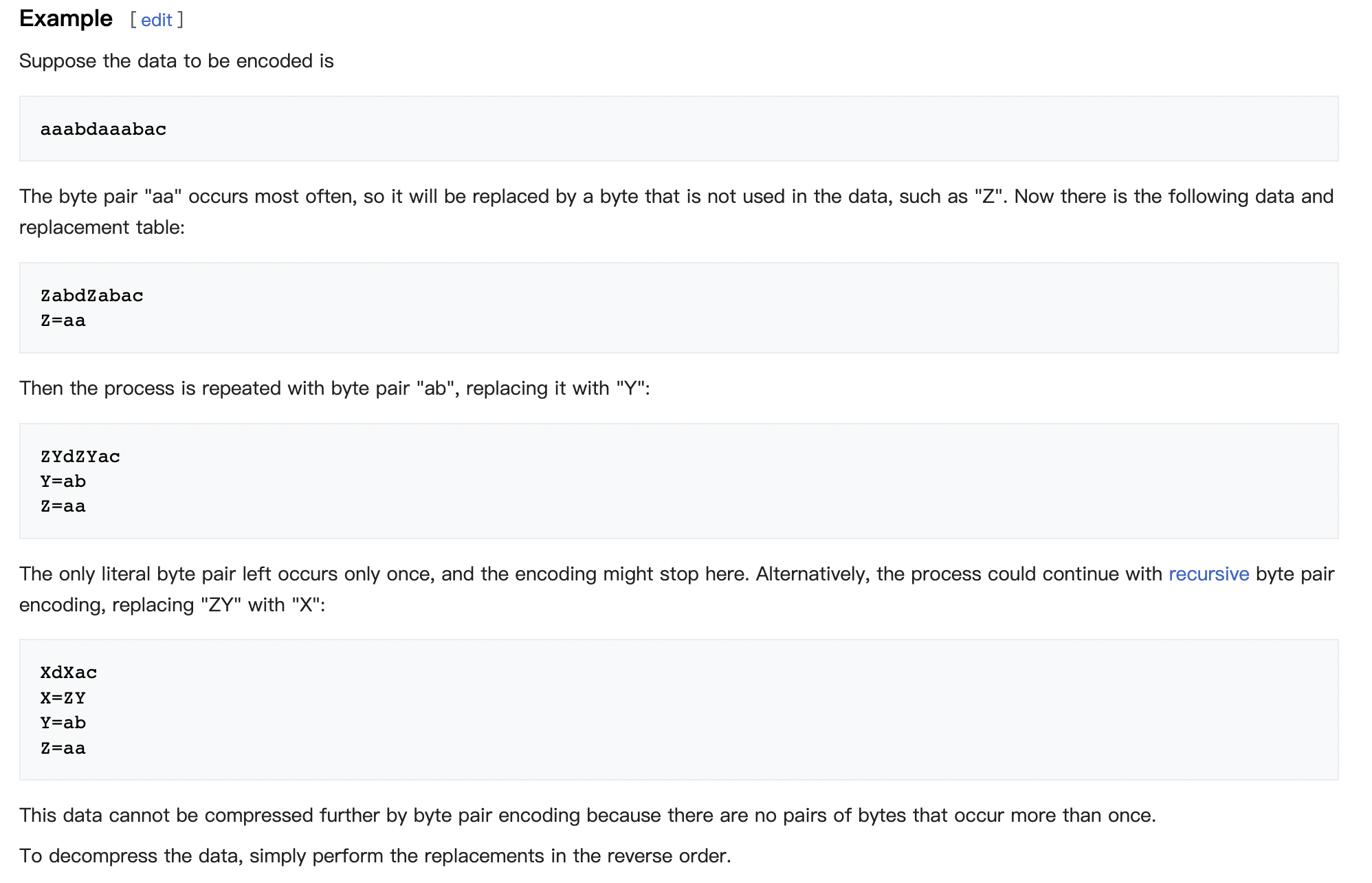
具体到Llama, 论文里说使用的是Google的SentencePiece方法。感兴趣的可以了解一下WordPiece、Unigram和SentencePiece算法。
拓展阅读:
Comments