1 简介
GLM模型是清华大学提出的一个LLM, 这个模型在中文数据集上的效果表现比较不错, 网络上也有一些针对这个模型的开发。
Paper: 《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》
Repo:
- official: https://github.com/THUDM/GLM
- huggingface: https://huggingface.co/THUDM/chatglm-6b/tree/main
- THUDM-ft: https://github.com/THUDM/FasterTransformer/tree/main/examples/pytorch/glm
2 算法原理
阅读GLM论文后,我总结了GLM的3个Feature:
独特的训练方式 / 优化目标: 这理解也是论文的核心卖点, 讲了一个“general” language model的故事。而所谓的general, 是指一个预训练好的模型,可以同事在NLU、条件生成和无条件生成任务中均表现很好。
一些模型结构的微调: 1)对layernorm和残差连接的顺序做了调整(将layernorm放在Block前可以提高大模型的精度及训练的稳定性 Ref: 参考文献1); 2)将Block内MLP中两个FC间的激活函数替换成了GELU(而非其它模型使用的ReLU)。GLM的Block内是Self-Attention + MLP组成, Self-Attention通常有两个矩阵参数, 一个是QKV矩阵用于计算qkv向量, 一个参数矩阵用于做特征变换(就是一个FC做矩阵乘); MLP通常有两个参数矩阵做特征变换(2次矩阵乘), 先升维,再降维, 有点借鉴ResNet bottleneck的思想。
2D位置编码: 服务于Feature 1, 使用Rotary Position Encoding。
2.1 模型结构简图
GLM-Block也是基本的Attention-Block + GLU-Block.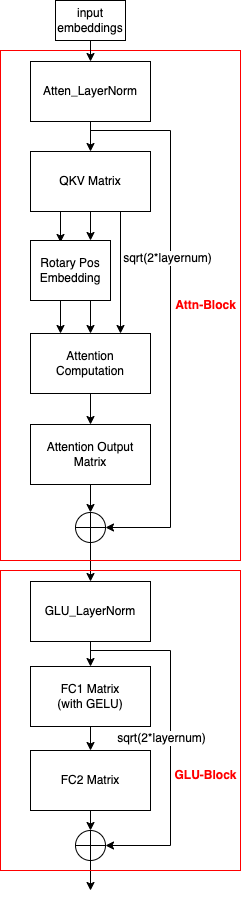
2.2 模型训练
数据处理:将输入tokens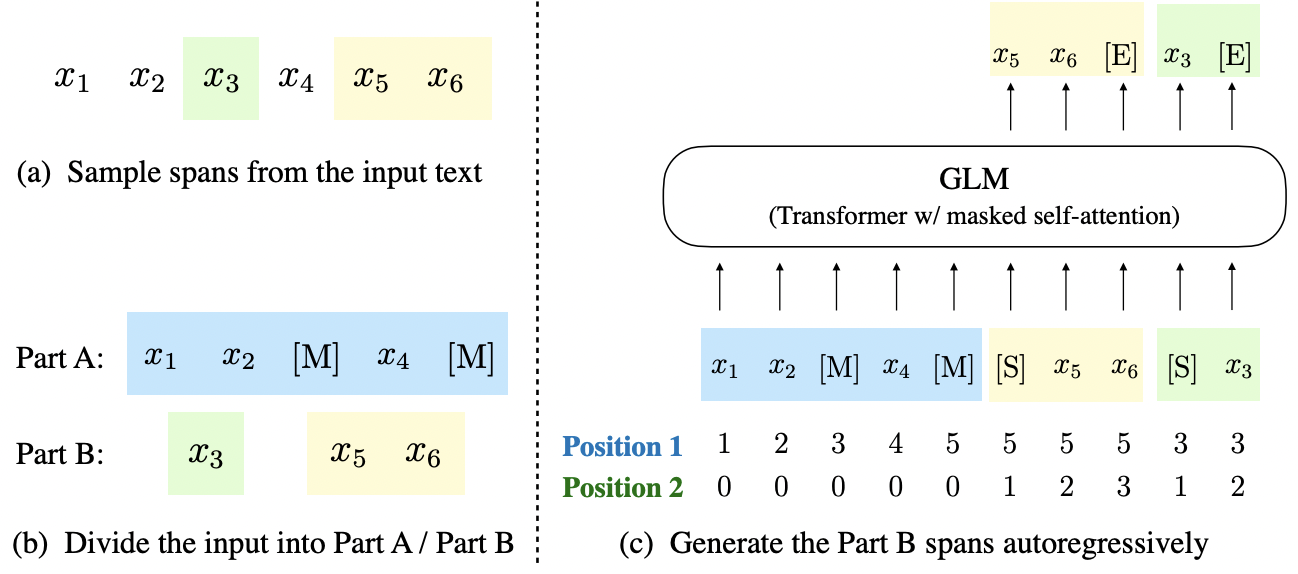
优化函数: 使用的是最大似然估计, 最大化生成概率的对数和。其中
GLM模型使用了P-tuning V2这一fine-tuing schema, 这个方法也是清华Jie Tang老师团队的工作。
2.3 Rotary位置编码
GLM工作使用的位置编码是国内追一科技提出的旋转位置编码(Rotary Position Embedding), 这一工作还是比较受领域内人员的认可, 像LLaMA也是采用了这种位置编码方案。
RoPE借助attention的计算, 实现了将绝对位置编码转换成相对位置编码。具体来说, 如果使用
经过一系列推导, 得到的变换
这是一个分块对角矩阵, 而每个分块又是一个2D旋转矩阵, 所以这种位置编码方式叫做旋转位置编码。另外, 由于这个矩阵是一个稀疏矩阵, 处于计算效率的考量, 可以用下面的计算来实现。
不同于原论文的旋转位置编码方法, GLM做了一点细微的改动: 每个token有两个position_id, 第一个id表示在输入
3 张量并行方案
使用的是NV的Megatron方案, Megatron并行的方案可以参考文献1. 如果要高度概括一下, 可以总结成以下三点:
- 对Self-Attention, 在head_num的维度上切分进行张量并行, 即每张卡都对部分头进行注意力计算;
- MLP的两层FC权重, 一个横切 + 一个纵切, 这样的切法可以减少一次通信次数;
- 每个Block内需要进行两次AllReduce操作, 一次是在attention_dense后, 一次是在MLP的最后一层FC后。
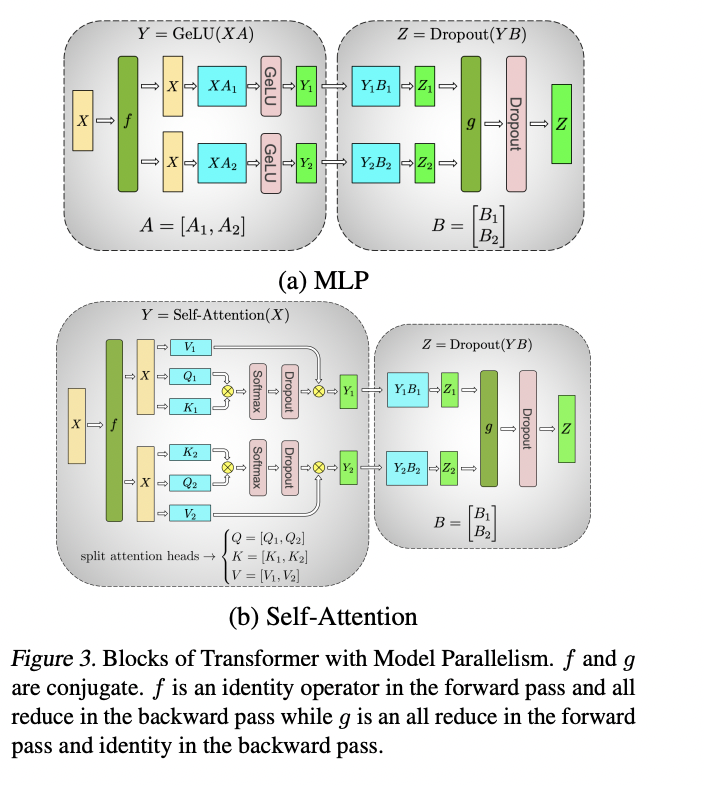
如果约定一下符号, Self-Attention的切分可以表示成:
- [b, s, h] x [h, 3h / p] = [b, s, 3h / p]: h是n个头的特征维数, 每张卡上负责n / p个头的注意力计算, 所以特征数是 n / p * h / n = h / p;
- [b, s, h / n] x [b, s, h / n].transpose = [b, s, s]: 每张卡都会为每个头计算attention score
- [b, s, s] x [b, s, h / n] = [b, s, h / n]: 每个头都计算出自己的value, 然后每张卡内的value值concatenate起来, 得到[b, s, h / p], (对应上图的Y1或Y2).
- [b, s, h /p] x [b, h / p, h] = [b, s, h], (对应上图的Z1或Z2)
- 将各张卡上的结果做一次all_reduce_sum
4 优化手段
- 针对特定硬件的算子优化
- 内存复用
- 算子融合
- 数据类型, e.g. INT8 / INT4
5 参考资料
1 《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism》
2 博采众长的旋转位置编码
Comments