1 量化原理
2 量化方式
2.1 从量化流程分类
一般来说, 可以按照如下方式对量化方法进行分类: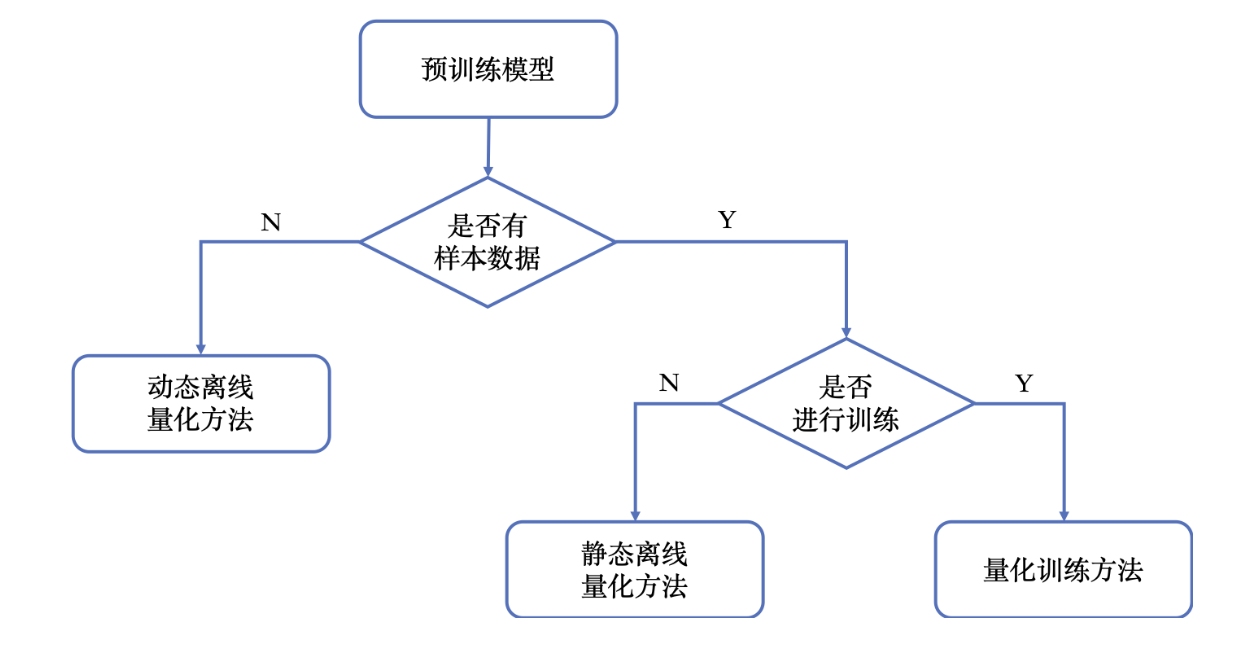
ONNX Runtime支持动态量化和静态量化两种方式:
- 动态量化:
scale和zero point会在前向推理时针对每个具体的输入去计算, 这会增加额外的计算开销, 但是量化后的精度下降更小。 - 静态量化: 需要在标定数据集上进行标定, 以此获得每个激活值的
scale和zero point。一般来说, 建议对RNN和Transformer类模型使用动态量化, 对CNN类模型使用静态量化。因为像Transformer类的大模型, 由于存在异常值(数值远大于一般值的数), 对激活的量化可能会带来较大的精度损失。
2.2 从量化后的数据类型分类
权重和激活量化后的数据类型都可以选择:
- Signed INT8
- Unsigned INT8
对ONNX Runtime而言。如果后端是CPU, 那么支持的数据类型是U8U8、U8S8(激活: unsigned int8, 权重: signed int8)和S8S8; 如果后端是GPU, 那么仅支持S8S8.
2.3 从量化后的数据是否对称分类
- 对称量化(
zero point为0,) - 非对称量化
3 量化模型格式
- Tensor Oriented: QDQ格式的量化模型。用Q和DQ来模拟量化, 并在QDQ中存储着统计好的量化参数
scale和zero point。 - Operator Oriented: QOperator格式的量化模型。有一些专门用于量化的算子, 比如
QLinearConv, 量化在算子内部完成。
5 数据标定算法
ONNX Runtime提供了两大类数据标定算法, 具体的实现可以在onnxruntime/python/tools/quantization/calibrate.py中阅读。
- MinMaxCalibrator
- HistogramCalibrator
5.1 基于最大值进行标定
选取最大值作为量化阈值。假设对于某层激活,前向了N个batch, 每次的最大值分别时
- 选取其中的最大值
作为量化阈值 - 取平均
作为量化阈值 - 取移动平均
5.2 基于统计直方图进行标定
这里ONNX Runtime给了两种基于直方图的标定方法:
- 基于交叉熵标定(EntroypyCalibrator)
基本思路: 选取最佳量化阈值, 最小化FP32分布和INT8分布的KL-Divergence[AKA相对熵(relative entropy)]。该标定算法参考了NV TensorRT的实现, NV的流程如下图所示:
问题: FP32分布如何统计得到?
根据NV的伪代码, 将FP32数据压缩成T个bin, 落在超出bin[T-1]的数值全部算在bin[T-1]里。这样就得到有T个值的分布P。
问题: INT8分布如何统计得到?
将T个bin压缩成128个bin, 得到一个有128个值的直方图。为了计算KL散度,再将这个分布扩充成和分布P拥有一样多数值的分布Q。
一个具体的计算例子如下图所示:
问题: 交叉熵和KL散度的关系?
P相对于Q的KL-Divergence的计算公式为:
P相对于Q的交叉熵的计算公式为:
P是一个固定的分布时, 最小化KL散度等价于最小化交叉熵。
- 基于累计分布函数标定(PercentileCalibrator)
通过FP32数据的累积分布函数(CDF), 配合percentile参数, 来选取量化阈值。当percentile参数趋于100%, 等价于minmax标定。
Comments